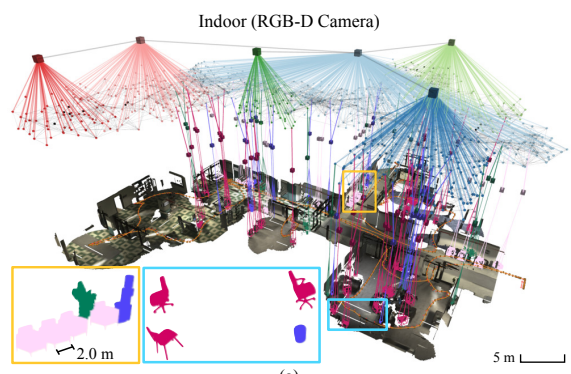
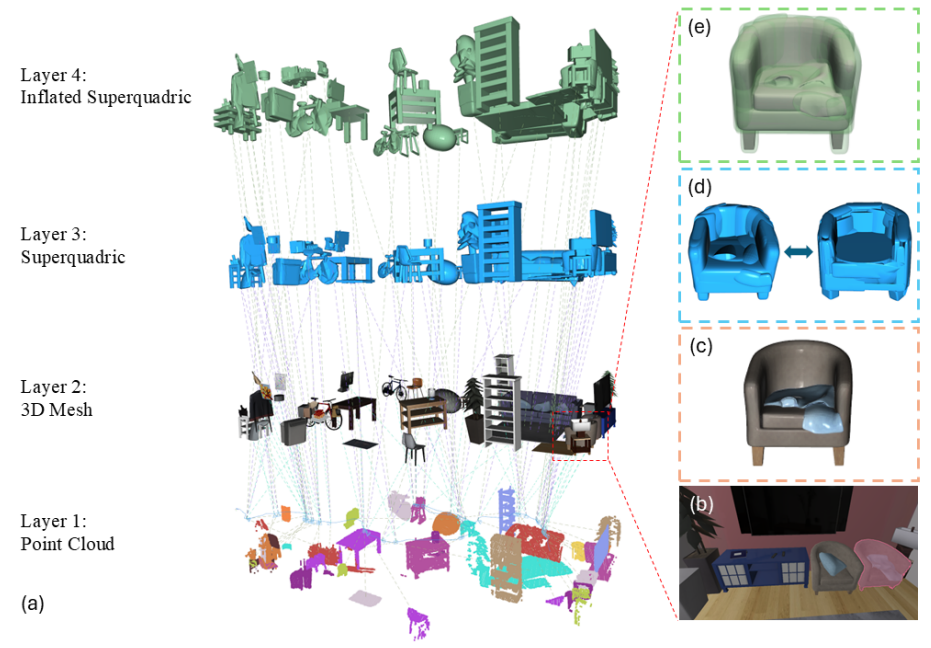
Abstract
This paper studies whether recent object pose and shape estimation methods are mature enough to serve as a reliable front end for robotic grasping. The authors compare a state-of-the-art end-to-end grasp synthesis approach against modular pipelines that first estimate object pose and shape, then generate 7-DoF parallel-jaw grasps with antipodal sampling from single-view RGB or RGB-D input. Across the experiments, the modular approaches generate more viable grasps, including for small objects where the end-to-end baseline struggles. The results also show that performance depends strongly on pose and shape accuracy, with cluttered scenes exposing current limitations. Finally, the paper demonstrates that single-view pose and shape estimates can be paired with vision-language models to produce language-conditioned grasps from RGB-D input.